[This is a series of posts about the AI, Blockchain, and IOT – and how they relate to evidence and compliance. We are not lawyers, and these are our technical comments. We hope they will be useful to folks working with the legal and compliance aspects of the documents. This is NOT a legal advice. For that, you need to consult an attorney]
What is Electronically Stored Information (ESI)?
According to the Wikipedia ESI is “Electronically stored information (ESI), for the purpose of the Federal Rules of Civil Procedure (FRCP) is information created, manipulated, communicated, stored, and best utilized in digital form, requiring the use of computer hardware and software”
You may notice that this definition is mostly concerned with distinguishing of ESI from paper. This is understandable in view of the fact that all of the discovery until the advent of ESI. You may also notice that this definition is bound to become insufficient at a certain point in the future. If we think of Blockchain, AI, and IOT, some aspects of these new ways of dealing with information will be missing from the standard ESI definition.
For example, IOT depends heavily on the network which is properly not the hardware or software. It is a means of communication. For example, if you compare hardware to food and software to a restaurant preparing the food for consumption, then the network is the delivery, or as the dictionary defines it, a way of sharing , given that in the network the information is often broken into packets and these packets are delivered through a combination of software and hardware, it is easy to see how the network may soon become a new discoverable ESI.
Take, for example TOR, TOR (anonymity network) is designed for anonymous browsing or, more generally, anonymous communication. It consists of seven thousand relays, so that every time that the user performs come activity on a website, he appears to come from a different place and be a different user. So now, it is conceivable to issue a discovery request against a user or a hosting organization but it will not read in terms of regular ESI.
For now, however, we can continue talking in terms of regular ESI, though we know full well that it may be modified soon. As the Wikipedia continues, “ESI has become a legally defined phrase as the U.S. government determined for the purposes of the FRCP rules of 2006 that promulgating procedures for maintenance and discovery for electronically stored information was necessary.”
In other words, the term “ESI” is a moniker for whatever may be requested in the discovery request which is not paper. Hence, the popular use of the term “eDiscovery.”
And the final quote, “Rule 34(a) enables a party in a civil lawsuit to request another party to produce and permit the requesting party or its representative to inspect, copy, test, or sample the following items in the responding party’s possession, custody, or control…”
For our purposes here, we need to investigate as deeply as we can what kinds of ESI exists, what new types of ESI appeared recently, especially born by Blockchain, AI, and IOT – and what new types will soon appear so that it is reasonable to talk about them now. Let us start with the standard ESI.
Standard ESI
There are literally thousands of file types, and usually they are characterized by their extensions. Probably the most common files are Microsoft Office and PST mailboxes. However, in evidence people usually cannot skip any file just because it was of a type that their eDiscovery software could not read. Therefore, one looks for the most powerful software to read multiple file format. And the most powerful software is probably provided by the open source project called Tika. Here is the link to Tika’s website: https://tika.apache.org/. Here is the Tika’s logo
![]()
Tika project was started in 2007 and it is by now twelve years old. An amazing number of eDiscovery software packages have Tika inside. By itself, Tika does not do file read or conversion; rather, Tika is an umbrella project that organizes libraries for reading specific file formats. For example, to read the PDF format, Tika uses PDFBox, for Microsoft Office file, it uses LibreOffice, and so on.
The architecture of Tika explains its preeminent place and popularity. When a new file format is needed, it is usually added to Tika by another library. Thus, it is very hard to compete with Tika, you will probably be simply included into Tika as one of the options.
I am well familiar with the developers in the Tika support group, having worked with them at DARPA Memex program (https://www.darpa.mil/program/memex) and through the needs of my FreeEed (http://freeeed.org/) software.
The creators and maintainers of Tika are a very dynamic and creative group of people. Their turnaround time on fixes is usually twenty-four hours, or a few days at most. At least that was my experience.You can easily take Tika for a spin. Download the latest version of tika-app-version.jar. For example, I am using tika-app-1.20.jar. Then run it with the following command
java -jar tika-app.jar
The result will be a screen as shown below

In addition to this screen, another screen will appear, that is of running Tika application itself. It is shown below in Figure 11.

To illustrate how Tika works, I followed the invitation displayed in the Figure 11 screen and dropped the document containing the chapter that I am working on, onto the Tika app screen. The result is shown below in Figure 12.

As you can see, Tika has understood the file type (Microsoft Office Word), its version (16), its author (Tom), and so on. “Tom” is actually not me, but probably the author of the document template that I started with (an interesting piece of evidence).
Tika found about three dozen different fields, usually called metadata. But this was just an illustration and a way to make it hands-on. Tika runs inside many eDiscovery software and helps it find all the information that then goes into the eDiscovery review.
A few interesting facts about Tika which are of practical importance.
- Tika does not believe the file extension. It may use it as hint, but the ultimate test is in the first few bytes of the file.
- Tika is extremely fast, and to make it even faster, one can run Tika as a server.
- Tika can open more than 1,400 file formats
The question of file extensions is an interesting one in its own right. It is a well-known device of hiding from eDiscovery by reassigning the extension. Once you do that, you are the only one who knows what real extension the file was. Now many eDiscovery packages will be confused. And the Microsoft Office software will definitely be confused, it is built for quick opening of files, not for the investigation, and if you renamed a Microsoft Word document (.docx) into an Excel (.xlsx) it will try to open the file as Excel. After some time, it will crash.
However, an astute reader can do a simple trick to verify the file type. She can run the “file” utility. Below is an example of running the “file” utility on the Mac computer.
![]()
The above figure illustrates running the “file” utility on the chapter that I am writing. As you can see, it correctly identified the file type as Microsoft Word 2007+. Well, Tika has a similar utility built in.
So far, we have covered the “standard” ESI formats in depth. Now you should have good idea of what they are and how to deal with them. You also know how to do the file investigation yourself, for any of the 1,400+ file types, verify the file type, and extract the metadata.
Databases and their unique challenges
To everyone who worked with eDiscovery, requests involving databases calls for hard work and are often a pain. Why is that? Databases have a unique element in their constructions, called a schema. A schema simply means database structure. We will deal more with databases schemas below but for now let’s just accept that each database has a unique structure and the challenge in database discovery will be to discover this schema, in the first place.
SQL Database
The preceding discussion only applies to an older, and a more common type of database, called SQL bases or more generally, SQL datastores. The SQL means Structured Query Language. The Wikipedia defines SQL as “domain-specific language used in programming and designed for managing data held in a relational database management system (RDBMS)”. (Please note the ‘domain-specific language’ label, we will be back to it later).
Again, following the Wikipedia, “SQL was one of the first commercial languages for Edgar F. Codd’s relational model. The model was described in his influential 1970 paper, “A Relational Model of Data for Large Shared Data Banks.” SQL became a standard of the American National Standards Institute (ANSI) in 1986”.
You can imagine that with the popularity of the SQL and with the availability of commercial implementation by Oracle, Microsoft, and many others, including the open source world, an enormous amount of information today is stored in SQL databases.
The trouble with the discovery of databases is that each database, as we already mentioned, has a different schema, or you may say, a different Catalog of how the data is stored and what it means. All is not lost, however, because you can write the software that will read the database and find out the schema. This software can then even generate the code (say, in Java) which will read the data contained in the database).
This is exactly the approach taken by Hive. Hive is a tool used in Hadoop for dealing with SQL data. The Figure below shows the architecture of Hive. In fact, for your discovery you can borrow the open source code from Hive and auto-discover your database. After that, your software will be able to produce the required information.
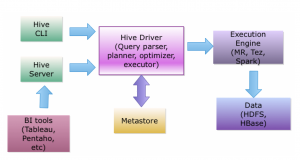
Thus far, we have covered SQL databases. Cumbersome as the discovery of databases may be, the SQL database have been around for more than thirty years and many people have already dealt with them. The potential problems may arise from the sheer size of the data stored on a SQL database. While we will be back to this problem as well, In the next blog let us turn to NoSQL databases, which are usually associated with very large data volumes, thus exacerbating the problem which we have just mentioned.
We have covered the file formats and SQL databases. However, if you want to know what is going in the Big Data world, you will need to go read the next instalment.
[The next in the Blog series “Legal Aspects of New Technologies: Blockchain, AI, And IOT” will cover Cloud Datastores, Hadoop and its format, Blockchain file format]